
RFC 1957 observes, discussing mail reading software that implements the popular POP3 protocol: “two popular clients require optional parts of the RFC. Netscape requires UIDL, and Eudora requires TOP.”
This reads like a complaint, but this tell me that Netscape’s mail reader (which these days is called Thunderbird) is well designed.
The rot started with RFC 1939, the standard for this protocol. This document specifies that UIDL is optional. This was a mistake. Without UIDL, the protocol is not reliable. I write this in the hope of persuading you that UIDL should not only be considered a requirement for a POP3 server, but that any client software that doesn’t require UIDL should not be trusted. I’m looking at you, Eudora!

What is UIDL and how does it fit into POP3?
UIDL is the “directory listing” command in POP3. When a client issues this request, the server responds with a list of “unique-id” strings that may as well be considered file names.
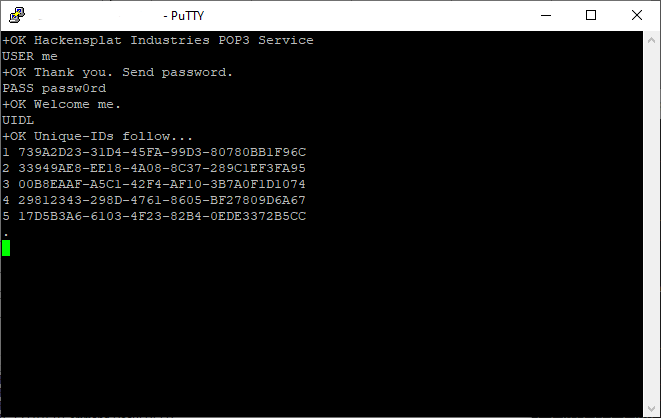
Each unique-id is paired with a numeric id, starting from 1. The other commands to download and delete messages all use these numeric ids. Each time the client reconnects, it will need to repeat the UIDL command so it knows which numeric ids refer to which messages.
For something as fundamental as a directory listing, it seems odd for that to be optional.
Without UIDL, the client needs to fall-back onto those numeric message ids alone. Instead of UIDL, the STAT command returns the number of messages in a mailbox. With that, the client can loop from 1 to n, downloading and deleting each one, leaving the mailbox empty once they have all been downloaded. As POP3 is explicitly designed for download-and-delete operation and not keeping the messages on the server, you might consider that UIDL is not necessary. So let us follow that road where we don’t have UIDL.

Living in a world without UIDL.
Operating POP3 without UIDL only works in an ideal world. If you had 100% reliable connections to the server then you might get away with it. Reality tells us the world is not ideal.
Let’s think about the step of deleting a message once you’ve downloaded it. You might think that DELE is the request to delete messages you’ve downloaded (or don’t want), but the request to actually delete messages is QUIT.
The client flags the messages to delete with DELE, but those deletes aren’t committed until the client later issues a QUIT request. If the connection stops before a QUIT, the server has to forget about those DELE commands and the messages all have to remain in the mailbox for when you reconnect. This is by design as you wouldn’t want your messages deleted if your client is in an unstable environment that can’t keep a connection open.
Consider though, what would happen if the underlying connection was dropped just as the client issued a QUIT request. You sent the request but no response came back.
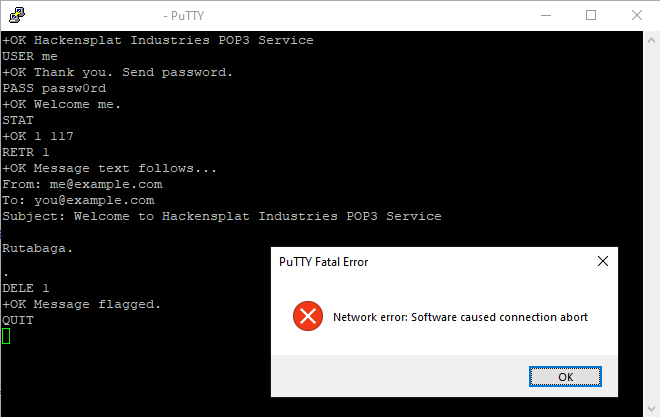
What happened? We don’t know. We can’t know. There are three reasonable possibilities…
- The QUIT command never arrived at the server. The server just saw the connection drop.
- The server couldn’t process the delete and responded with an error, which got lost.
- The server successfully deleted the messages, but the response got lost.
You asked for some messages to be deleted, but you don’t know if your instruction was processed or not. The only way to find out is to reconnect (when you can) and see if the messages you asked the server to delete has gone or not.
Let’s say that time has passed and the client is finally able to reconnect to the server again. Last time, the client downloaded a single message and may or may not have deleted it. Now we’ve reconnected we find a single message in the mailbox. Is this the one we deleted before or a new one that’s arrived in the interim? A handy directory listing would be real useful right about now!
This is why I would mistrust any mail reading software that didn’t require that a mail server implements UIDL. Messages might get downloaded twice or wrongly deleted if the wrong assumptions are made.

The alternatives to UIDL are all unreasonable.
If the above doesn’t convince you that UIDL is necessary, this section is to answer anticipated responses that UIDL is not necessary. Nuh huh!
(If you are already convinced and you don’t want to read my responses to anticipated arguments, you can skip this section.)
“That scenario you describe won’t ever happen in reality.”
Stage one: Denial.
Where is this perfect world where connections don’t stop working at the worst possible time? Where database updates happen instantly? I want to live there!
Think about what a server needs to do to process a QUIT command. Many flagged messages will need to be modified in an atomic transaction such that they won’t be included next time. Indexes will need to be updated and the dust needs to settle before the server can send its acknowledgement. During this time, the underlying TCP connection will be sitting there idle, looking just like a timeout error.
“We wouldn’t have a problem if mail servers were better engineered!”
Stage two: Anger
If your requirements of a mail server include underlying connections over the public internet that never fail, I think your requirements are a little unreasonable.
“So I occasionally see two copies of a message in my mailbox. Big whoop!”
Stage three: Bargaining.
If that started happening in software I was using, I’d file a bug report.
“There are other ways POP3 can resolve this issue.”
Stage four: Depression.
Alas, all of these alternatives that POP3 provide are unreasonable.
You could use the response to LIST as a fall-back? This command requests the size in bytes of each message. Most messages are long enough that they will have a unique size, but this isn’t reliable. Messages are often going to have the same size as others just by accident.
You could use TOP to retrieve just the header and extract something from that to track messages? Problem there is that no single header is a reliable identity. Two adjacent messages might have the same date or the same subject. The closest candidate for a suitable identity is Message-ID but this is generated by the sender, who might not include it or might reuse IDs. If we’re relying on the POP3 server to add them or modify duplicates provided by a sender, we’re back to relying on optional features.
You could use the TOP response and hash the entire header? This could work except message headers can change. I first saw this when experimenting with a mail server and observed that if I connected to a mailbox using IMAP, it would leave IMAP’s version of a unique identity in the header which wasn’t there before. As well as that, anti-spam systems might re-examine a mailbox’s contents and update the anti-spam or anti-virus headers. Any of these changes would look like a new message.
(As well as all that, TOP is itself an optional command, just like UIDL.)
You could download the entire message again and ignore it if you already have it? This would be ultimate fall-back. While I’ve seen headers change, the message body seems to be immutable. This is still an unreasonable situation. We’re downloading the whole message again, just because the server chose not to implement a simple directory-listing command.
Am I certain that the message body is immutable? No, not at all. If someone commented that mail server XYZ updates messages in the form of a MIME attachment, I wouldn’t be at all surprised.
Update – A digression on the Message-ID header
(Added 28/Jan/2021)
I am grateful to commenter “theamk” on Hacker News, who responded to me when I shared this post. To my dismissal of Message-ID as a means of de-duplication, they noted that RFC standards require that Message-IDs must be generated as unique.
I have experienced senders who have broken the protocol, sending many different messages with the same Message-ID. I do not argue these senders were in the wrong but that the POP3 server is not in a reasonable position to correct the situation.
If the server actively corrected the situation and replaced the reused Message-ID header with its own unique value, the message would not be a faithful reproduction of the message as sent any more and further damage any scope for auditing.
If the server discarded or rejected the message with a reused Message-ID, it would open up means for an attacker to predict the Message-ID a legitimate sender is going to use and send a message with that ID first, causing the legitimate sender’s message to be lost. There’s nothing stopping a sender from using someone else’s Message-ID pattern. (Maybe senders should use only unpredictable strings, but wishing it so won’t make it happen.)
This is also to say nothing of the situation when the messages served up don’t have any Message-ID, which I’ve seen happen with messages exchanged within the local server only. (IE. Not routed over the public internet’s mail servers.) None of the small number of services inside the box from the original composer to the POP3 delivery agent supplied a Message-ID when it was missing, so the message turned up with the basic To/From/Subject/etc headers and a Received header, but no Message-ID.
Acceptance?
Because the alternatives are so unreasonable, I consider UIDL a requirement for handling POP3. Servers that don’t implement UIDL are bad servers. Clients that can work without UIDL are unreliable.
Still not convinced? Please leave a comment where you saw this piece posted.

IMAP does it wrong.
The other popular mail-reading protocol is IMAP. In contrast to POP3’s download-and-delete model, IMAP’s model is that messages to stay on the server and are only downloaded when the client wishes to read it. This model enables mail readers on low-storage devices such as smartphones.
With IMAP, the IDs are restricted to numeric values and always go upwards, in contrast to the free-for-all “any printable ascii except spaces” allowed by POP3. While this may be nice for the client, by requiring a single source of incrementing ID numbers, it complicates matters for anyone wishing to implement an IMAP server using a distributed database as a back-end.
But the worse thing about IMAP’s message identity system is that the standard permits the server to discard any IDs it has assigned by updating a mailbox’s UIDVALIDITY property. If this value ever changes, it is a signal to the client that any unique IDs it may have remembered are no longer valid.
A client needs a reliable way to identify messages between connections to recover from an unknown state. It does not need for servers to have a license to be unreliable.
If a mail server that implements IMAP wants any respect from me, it would document that its UIDVALIDITY value is fixed and will never change and that the unique-ids it generates are reliable.
POP3 does it wrong too.
If I’m going to criticize IMAP for flaws in its unique ID system, I should address flaws in POP3’s system too, having spent most of this article praising it.
Quoth RFC 1939: “The server should never reuse an unique-id in a given maildrop,” (good) “for as long as the entity using the unique-id exists.” (no!)
Consider that worst case scenario. The client flags a single message to be deleted and finally issues a QUIT command to complete the translation. The server successfully processes the request but the response to the client is lost. As far as the server is concerned, the message is gone and there’s no problem, but as far as the client knows, the continued existence of that message is unknown.
Now consider a new message arrives on the mail server and because the RFC says it can, it assigns the same unique ID to this new message as the one that was just deleted. The client eventually reconnects and requests the list of unique IDs and finds the ID of the message it wanted to delete is still there. It doesn’t know the server used its right to reuse unique IDs and that this is actually a new message!
Now, I’ve never seen a mail server actually reuse a unique ID. The clever people who have developed mail servers in the real world seem to understand that reusing IDs is not something you ever want to do, even if the RFC says you can.
RFC 1939 also says, “this specification is intended to permit unique-ids to be calculated as a hash of the message. Clients should be able to handle a situation where two identical copies of a message in a maildrop have the same unique-id.”
Unique IDs don’t have be unique? Ugh.
This allowance only applies to identical messages. In reality, messages are never identical. After bouncing around the internet and going through various anti-spam and anti-virus servers, messages do accumulate a frightening number of Received: headers left behind from each intermediate hand-over. Each one with a time-stamp and its own ID number. Any one of these is enough to produce a distinct hash.

Picture Credits. (All Creative-Commons licensed.)
“Listening to Radio Karnali” by “BBC World Service”.
“List 84” by “Weisbaden 2010”.
“The Time of Sunset” by Joy Sarah Nawati.
“Future” by “Legosz”.
“PuTTY screen-shots” by me.